

I manage a 40-person software company. Last year, around September, I sat down with our department leads and mapped out how everyone was spending their time. The numbers were grim. Across customer support, sales, content, engineering, and finance, we were burning roughly 135 hours per week on tasks that were repetitive, predictable, and — most importantly — not the work our people were actually hired to do.
Support reps were answering the same fifteen questions over and over. Our sales team was manually scoring leads from a spreadsheet. Content writers spent half their time on research before they wrote a single paragraph. Engineers reviewed boilerplate pull requests that could’ve been checked automatically. Our finance manager spent every Friday compiling reports from four different systems.
We decided to fix this with AI agents. Not a single monolithic AI system, but different agents for different jobs. The rollout took about four months. Some of it worked beautifully. Some of it failed in ways I should have anticipated. Here’s what happened.
The First Mistake: Treating All AI Agents the Same
My initial instinct was to buy one AI platform and point it at everything. That instinct was wrong. The support team’s problems were completely different from the sales team’s problems. A chatbot that routes FAQ questions doesn’t need the same architecture as a system that scores leads based on behavioral patterns.
Once I started reading about the different types of AI agents — reactive, model-based, goal-based, learning, autonomous — the picture got clearer. Each type operates at a different level of complexity and autonomy. Matching the right type to the right problem turned out to be the single most important decision we made.
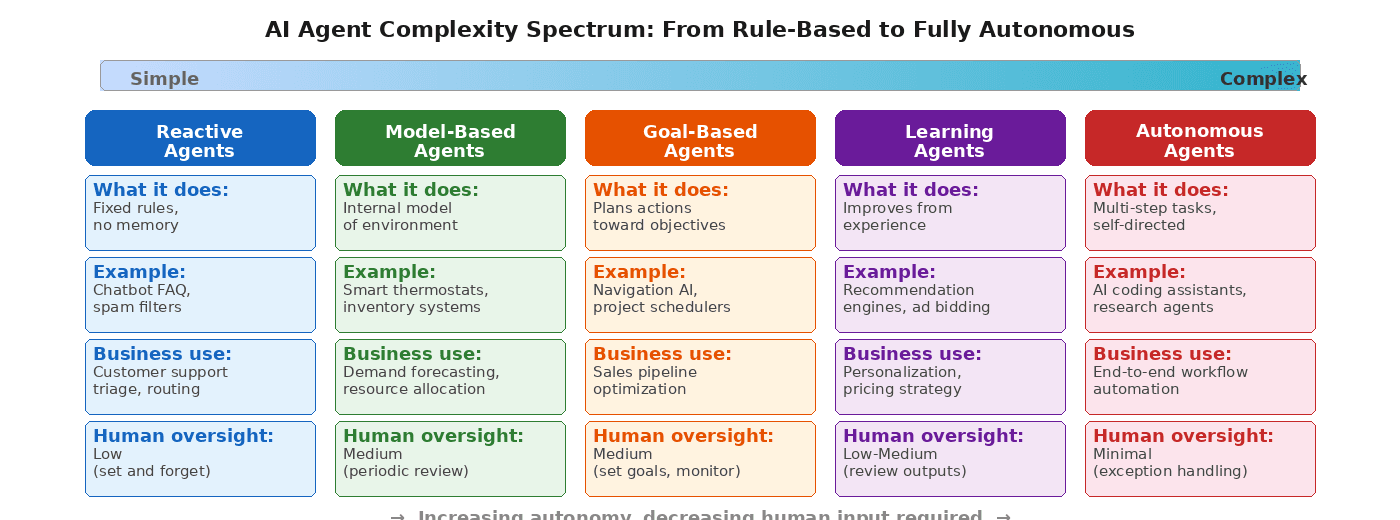
What We Deployed, Department by Department
Customer Support: A Reactive Chatbot
We started with the simplest possible agent. A rule-based chatbot that recognized common questions and served pre-written answers. No machine learning, no natural language understanding beyond keyword matching. It handled password resets, billing inquiries, and feature availability questions.
The result: our support team went from spending 45 hours per week on tier-1 tickets to about 12. The chatbot deflected roughly 70% of incoming queries. The remaining 30% — complex issues, angry customers, edge cases — went straight to human agents who now had the bandwidth to actually help people instead of copy-pasting the same response for the twentieth time that day.
Sales: A Learning Agent for Lead Scoring
Our sales reps were manually reviewing every inbound lead against a checklist: company size, industry, engagement level, source. It took about 30 hours a week across the team. We replaced this with a learning agent that analyzed historical conversion data and scored new leads automatically.
The first two weeks were rough. The model’s scoring didn’t match our reps’ intuition at all. We almost pulled the plug. Then our data person pointed out that the model was actually flagging leads our reps had been overlooking — smaller companies with high engagement scores that converted at 3x the rate of the enterprise leads we’d been prioritizing. We adjusted our sales process, not the model. Close rates went up 15% in the following quarter.
Content Production: A Goal-Based Research Agent
Our writers were spending 10-12 hours per article on research alone: reading competitor content, pulling statistics, finding expert quotes, structuring outlines. We deployed a goal-based agent that took a topic brief and produced a research package: relevant data points, source links, a suggested outline, and a gap analysis showing what competitors hadn’t covered.
The writers still did all the actual writing. The agent handled the grunt work. Article production time dropped from 25 hours to about 8 across the team. More importantly, the research quality improved because the agent was systematic in a way that humans doing repetitive searches tend not to be after their fourth article of the week.
Engineering: An Autonomous Code Review Agent
This was the riskiest deployment. We set up an autonomous agent that reviewed pull requests for style violations, security patterns, test coverage, and common bugs. It ran on every PR before a human reviewer looked at it.
The first month was noisy. Too many false positives. Engineers started ignoring the agent’s comments, which defeated the purpose. We spent two weeks tuning the rules and reducing the scope to only flag high-confidence issues. After that, it started saving about 14 hours per week of review time, and our bug-escape rate to production dropped by about 20%.
Finance: A Model-Based Reporting Agent
Our finance manager spent every Friday pulling data from Stripe, QuickBooks, our CRM, and Google Sheets, then assembling it into a weekly report. We built a model-based agent that connected to all four systems, aggregated the numbers, and generated the report automatically by Thursday evening.
This was the cleanest win. Fifteen hours per week compressed to three (mostly spent reviewing the output and adding commentary). Our finance manager started using Fridays for actual financial analysis instead of data wrangling.

Three Lessons From the Rollout
Match the Agent to the Problem, Not the Hype
We could have deployed a sophisticated LLM-based system for customer support. It would have been slower to implement, harder to debug, and more expensive to run — for a problem that keyword matching solved perfectly well. The simplest agent that gets the job done is the right choice. Save complexity for problems that actually require it.
Give Every Agent a Two-Week Probation Period
Our sales and engineering agents both struggled in their first two weeks. If we’d judged them on initial performance, we’d have scrapped both. Instead, we gave each deployment a two-week window where the agent ran alongside the existing process, and we collected feedback without making any permanent changes. That buffer period was the difference between a failed experiment and a permanent improvement.
Humans Still Own the Judgment Calls
None of our agents make final decisions. The chatbot escalates anything ambiguous. The lead scorer ranks, but reps decide who to call. The code reviewer flags, but engineers approve. Removing humans from the loop entirely is tempting when the numbers look good, but the moment an edge case hits — and it will — you need someone who can exercise judgment, not just follow a pattern.
Where We Are Now
Twelve months in, we’re saving roughly 96 hours per week across the company. That’s the equivalent of 2.4 full-time employees worth of labor redirected from repetitive tasks to work that actually requires human thinking: strategy, relationship building, creative problem-solving, the things our people were hired to do in the first place.
The financial impact matters, but the morale impact surprised me more. People are happier when they’re not doing the same task for the fortieth time this week. Our last engagement survey showed the highest satisfaction scores we’ve had since founding the company. I can’t attribute all of that to AI agents, but I know removing drudgery played a part.
If you’re leading a team of any size and haven’t explored this yet, start with one department and the simplest agent that fits. Don’t try to automate everything at once. Pick the task your team complains about most, match it to the right type of agent, and give it a real trial. The 96-hour number didn’t happen in a week. It happened one department at a time, over four months, with plenty of wrong turns along the way.




{kind=link}